Cloud Edventures
AI systems fail.
LLM APIs timeout. Containers crash. Queues overflow. External tools return invalid responses.
If you're running AI agents or LLM-powered SaaS in production, fault tolerance is not optional — it's required.
This guide walks through how to design a resilient, fault-tolerant AI pipeline on AWS.
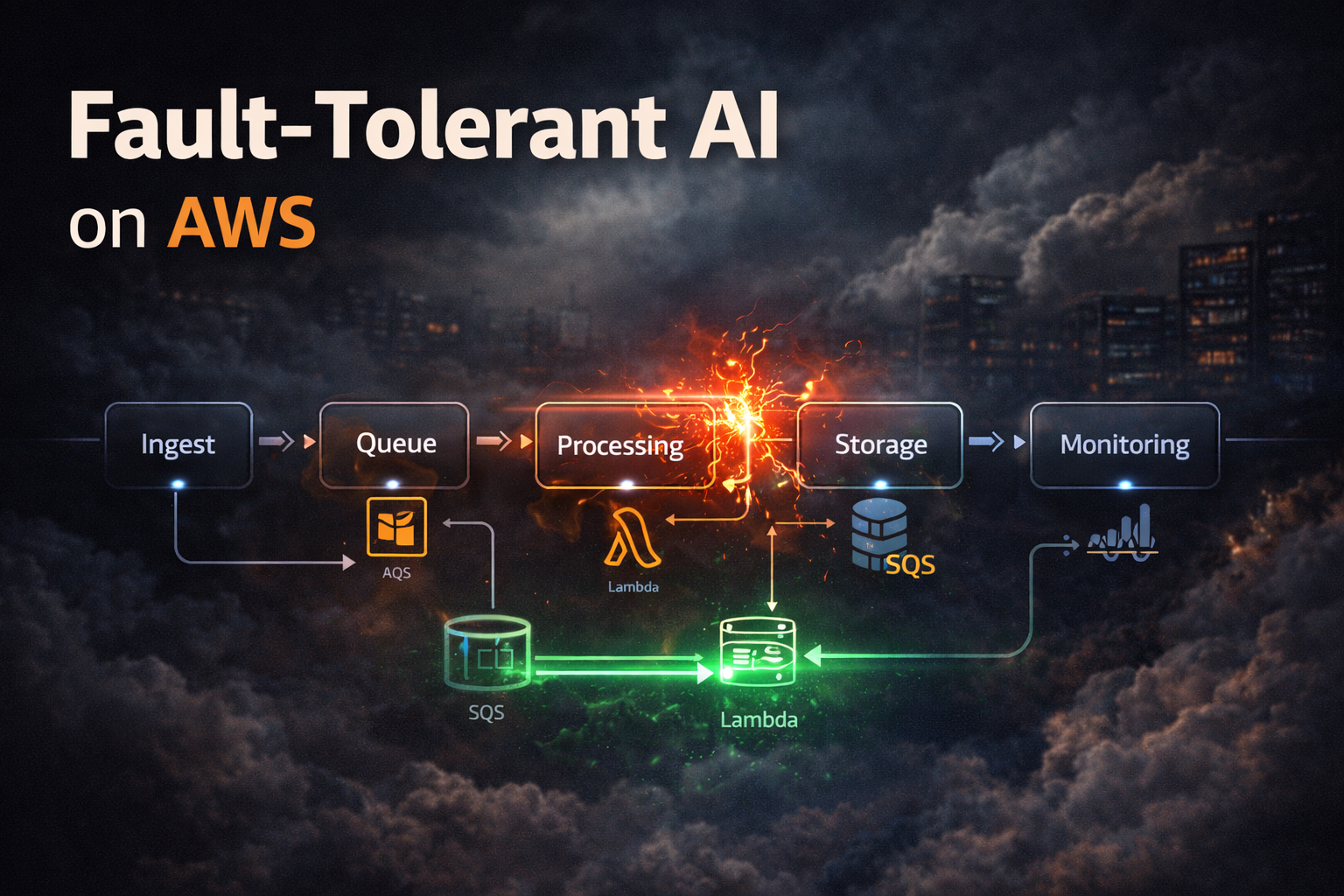
A fault-tolerant pipeline continues operating even when individual components fail.
Instead of crashing the entire workflow, it:
AI pipelines must assume failure at every step.
Core components:
Each component isolates responsibility.
Never let your API directly call heavy AI tasks.
Instead:
If a worker crashes, the message returns to the queue.
LLM APIs can fail temporarily.
Implement:
Avoid infinite retry loops.
Attach a dead-letter queue to SQS.
If a message fails after multiple retries:
This prevents stuck pipelines.
AI workers should be stateless.
Do not store memory inside container RAM.
Use:
This allows containers to restart safely.
If a task retries, it must not duplicate work.
Use:
Ensure repeated execution produces the same outcome.
For multi-step AI tasks:
Step Functions provide:
Enable:
Containers should restart automatically on failure.
Track these metrics:
Set CloudWatch alarms for abnormal patterns.
AI pipelines must guard against:
Always validate outputs before execution.
Deploy across multiple Availability Zones.
Ensure:
This protects against infrastructure-level failures.
Your system must survive all of them.
If any are missing, your pipeline is fragile.
AI systems amplify failure because they are probabilistic.
Building fault tolerance is about assuming everything will fail — and designing for recovery.
Resilient AI pipelines are not built accidentally. They are engineered deliberately.
42 people reacted to this article
Written by Cloud Edventures
Previous
No more articles
Next
No more articles
